Language Modeling
Semantic embeddings, such as Word2Vec and GloVe, are in fact a first step towards language modeling - creating models that somehow understand (or represent) the nature of the language.
The main idea behind language modeling is training them on unlabeled datasets in an unsupervised manner. This is important because we have huge amounts of unlabeled text available, while the amount of labeled text would always be limited by the amount of effort we can spend on labeling. Most often, we can build language models that can predict missing words in the text, because it is easy to mask out a random word in text and use it as a training sample.
Training Embeddings
In our previous examples, we used pre-trained semantic embeddings, but it is interesting to see how those embeddings can be trained. There are several possible ideas the can be used:
- N-Gram language modeling, when we predict a token by looking at N previous tokens (N-gram)
- Continuous Bag-of-Words (CBoW), when we predict the middle token $W_0$ in a token sequence $W_{-N}$, …, $W_N$.
- Skip-gram, where we predict a set of neighboring tokens {$W_{-N},\dots, W_{-1}, W_1,\dots, W_N$} from the middle token $W_0$.
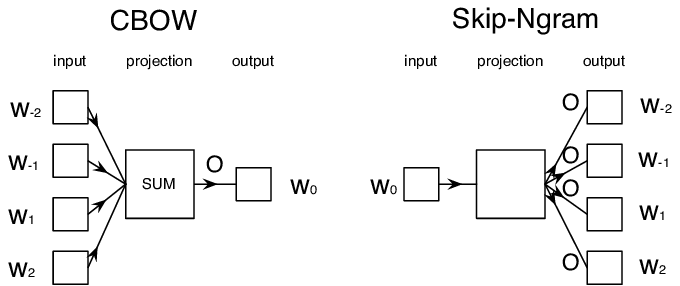
Image from this paper
The most popular algorithms for training word embeddings are Word2Vec and GloVe. Both of them are based on the idea of predicting a word from its context, but they differ in the details of how this is done.
Conclusion
In the previous lesson we have seen that words embeddings work like magic! Now we know that training word embeddings is not a very complex task, and we should be able to train our own word embeddings for domain specific text if needed.
Review & Self Study
- Official PyTorch tutorial on Language Modeling.
- Official TensorFlow tutorial on training Word2Vec model.
- Using the gensim framework to train most commonly used embeddings in a few lines of code is described in this documentation.
- Word2Vec in TensorFlow and Word2Vec in PyTorch tutorials.